曹工說JDK源碼(1)–ConcurrentHashMap,擴容前大家同在一個哈希桶,為啥擴容后,你去新數組的高位,我只能去低位?
如何計算,一對key/value應該放在哪個哈希桶
大家都知道,hashmap底層是數組+鏈表(不討論紅黑樹的情況),其中,這個數組,我們一般叫做哈希桶,大家如果去看jdk的源碼,會發現裏面有一些變量,叫做bin,這個bin,就是桶的意思,結合語境,就是哈希桶。
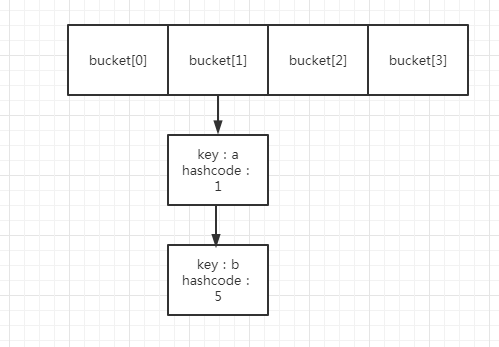
這裏舉個例子,假設一個hashmap的數組長度為4(0000 0100),那麼該hashmap就有4個哈希桶,分別為bucket[0]、bucket[1]、bucket[2]、bucket[3]。
現在有兩個node,hashcode分別是1(0000 0001),5(0000 0101). 我們當然知道,這兩個node,都應該放入第一個桶,畢竟1 mod 4,5 mod 4的結果,都是1。
但是,在代碼里,可不是用取模的方法來計算的,而是使用下面的方式:
int entryNodeIndex = (tableLength - 1) & hash;
應該說,在tableLength的值,為2的n次冪的時候,兩者是等價的,但是因為位運算的效率更高,因此,代碼一般都使用位運算,替代取模運算。
下面我們看看具體怎麼計算:
此處,tableLength即為哈希表的長度,此處為4. 4 – 1為3,3的二進製表示為:
0000 0011
那麼,和我們的1(0000 0001)相與:
0000 0001 -------- 1
0000 0011 -------- 3(tableLength - 1)
相與(同為1,則為1;否則為0)
0000 0001 -------- 1
結果為1,所以,應該放在第1個哈希桶,即數組下標為1的node。
接下來,看看5這個hashcode的節點要放在什麼位置,是怎麼計算:
0000 0101 -------- 5
0000 0011 -------- 3(tableLength - 1)
相與(同為1,則為1;否則為0)后結果:
0000 0001 -------- 1
擴容時,是怎麼對一個hash桶進行transfer的
此處,具體的整個transfer的細節,我們本講不會涉及太多,不過,大體的邏輯,我們可以來想一想。
以前面為例,哈希表一共4個桶,其中bucket[1]裏面,存放了兩個元素,假設是a、b,其hashcode分別是1,5.
現在,假設我們要擴容,一般來說,擴容的時候,都是新建一個bucket數組,其容量為舊錶的一倍,這裏舊錶為4,那新表就是8.
那,新表建立起來了,舊錶里的元素,就得搬到新表裡面去,等所有元素都搬到新表了,就會把新表和舊錶的指針交換。如下:
java.util.concurrent.ConcurrentHashMap#transfer
private transient volatile Node<K,V>[] nextTable;
transient volatile Node<K,V>[] table;
if (finishing) {
// 1
nextTable = null;
// 2
table = nextTab;
// 3
sizeCtl = (tabLength << 1) - (tabLength >>> 1);
return;
}
-
1處,將field:nextTable(也就是新表)設為null,擴容完了,這個field就會設為null
-
2處,將局部變量nextTab,賦值給table,這個局部變量nextTab里,就是當前已經擴容完畢的新表
-
3處,修改表的sizeCtl為:假設此處tabLength為4,tabLength << 1 左移1位,就是8;tabLength >>> 1,右移一位,就是2,。8 – 2 = 6,正好就等於 8(新表容量) * 0.75。
所以,這裏的sizeCtl就是,新表容量 * 負載因子,超過這個容量,基本就會觸發擴容。
ok,接着說,我們要怎麼從舊錶往新表搬呢? 那以前面的bucket[1]舉例,遍歷這個鏈表,計算各個node,應該放到新表的什麼位置,不就完了嗎?是的,理論上這麼寫就完事了。
但是,我們會怎麼寫呢?
用hashcode對新bucket數組的長度取余嗎?
jdk對效率的追求那麼高,肯定不會這麼寫的,我們看看,它怎麼寫的:
java.util.concurrent.ConcurrentHashMap#transfer
// 1
for (Node<K,V> p = entryNode; p != null; p = p.next) {
// 2
int ph = p.hash;
K pk = p.key;
V pv = p.val;
// 3
if ((ph & tabLength) == 0){
lowEntryNode = new Node<K,V>(ph, pk, pv, lowEntryNode);
}
else{
highEntryNode = new Node<K,V>(ph, pk, pv, highEntryNode);
}
}
-
1處,即遍歷舊的哈希表的某個哈希桶,假設就是遍歷前面的bucket[1],裏面有a/b兩個元素,hashcode分別為1,5那個。
-
2處,獲取該節點的hashcode,此處分別為1,5
-
3處,如果hashcode 和 舊錶長度相與,結果為0,則,將該節點使用頭插法,插入新表的低位;如果結果不為0,則放入高位。
ok,什麼是高位,什麼是低位。擴容后,新的bucket數組,長度為8,那麼,前面bucket[1]中的兩個元素,將分別放入bucket[1]和bucket[5].
ok,這裏的bucket[1]就是低位,bucket[5]為高位。
首先,大家要知道,hashmap中,容量總是2的n次方,請牢牢記住這句話。
為什麼要這麼做?你想想,這樣是不是擴容很方便?
以前,hashcode 為1,5的,都在bucket[1];而現在,擴容為8后,hashcode為1的,還是在newbucket[1],hashcode為5的,則在newbucket[5];這樣的話,是不是有一半的元素,根本不用動?
這就是我覺得的,最大的好處;另外呢,運算也比較方便,都可以使用位運算代替,效率更高。
好的,那我們現在問題來了,下面這句的原理是什麼?
if ((ph & tabLength) == 0){
lowEntryNode = new Node<K,V>(ph, pk, pv, lowEntryNode);
} else{
highEntryNode = new Node<K,V>(ph, pk, pv, highEntryNode);
}
為啥,hashcode & 舊哈希表的容量, 結果為0的,擴容后,就會在低位,也就是維持位置不變呢?而結果不為0的,擴容后,位置在高位呢?
背後的位運算原理(大白話)
代碼里用的如下判斷,滿足這個條件,去低位;否則,去高位。
if ((ph & tabLength) == 0)
還是用前面的例子,假設當前元素為a,hashcode為1,和哈希桶大小4,去進行與運算。
0000 0001 ---- 1
0000 0100 ---- 舊哈希表容量4
&運算(同為1則為1,否則為0)
結果:
0000 0000 ---- 結果為0
ok,這裏算出來,結果為0;什麼情況下,結果會為0呢?
那我們現在開始倒推,什麼樣的數,和 0000 0100 相與,結果會為0?
???? ???? ----
0000 0100 ---- 舊哈希表容量
&運算(同為1則為1,否則為0)
結果:
0000 0000 ---- 結果為0
因為與運算的規則是,同為1,則為1;否則都為0。那麼,我們這個例子里,舊哈希表容量為 0000 0100,假設表示為2的n次方,此處n為2,我們僅有第三位(第n+1)為1,那如果對方這一位為0,那結果中的這一位,就會為0,那麼,整個數,就為0.
所以,我們的結論是:假設哈希表容量,為2的n次方,表示為二進制后,第n+1位為1;那麼,只要我們節點的hashcode,在第n+1位上為0,則最終結果是0.
反之,如果我們節點的hashcode,在第n+1位為1,則最終結果不會是0.
比如,hashcode為5的時候,會是什麼樣子?
0000 0101 ---- 5
0000 0100 ---- 舊哈希表容量
&運算(同為1則為1,否則為0)
結果:
0000 0100 ---- 結果為4
此時,5這個hashcode,在第n+1位上為1,所以結果不為0。
至此,我們離答案好像還很遠。ok,不慌,繼續。
假設現在擴容了,新bucket數組,長度為8.
a元素,hashcode依然是1,a元素應該放到新bucket數組的哪個bucket里呢?
我們用前面說的這個算法來計算:
int entryNodeIndex = (tableLength - 1) & hash;
0000 0001 ---- 1
0000 0111 ---- 8 - 1 = 7
&運算(同為1則為1,否則為0)
結果:
0000 0001 ---- 結果為1
結果沒錯,確實應該放到新bucket[1],但怎麼推論出來呢?
// 1
if ((ph & tabLength) == 0){
// 2
lowEntryNode = new Node<K,V>(ph, pk, pv, lowEntryNode);
}
也就是說,假設一個數,滿足1處的條件:(ph & tabLength) == 0,那怎麼推論出2呢,即應該在低位呢?
ok,條件1,前面分析了,可以得出:
這個數,第n+1位為0.
接下來,看看數組長度 – 1這個數。
| 數組長度 | 2的n次方 | 二進製表示 | 1出現的位置 | 數組長度-1 | 數組長度-1的二進制 |
|---|---|---|---|---|---|
| 2 | 2的1次方 | 0000 0010 | 第2位 | 1 | 0000 0001 |
| 4 | 2的2次方 | 0000 0100 | 第3位 | 3 | 0000 0011 |
| 8 | 2的3次方 | 0000 1000 | 第4位 | 7 | 0000 0111 |
好了,兩個數都有了,
???????0??????? -- 1 節點的hashcode,第n + 1位為0
000000010000000 -- 2 老數組
000000100000000 -- 3 新數組的長度,等於老數組長度 * 2
000000011111111 -- 4 新數組的長度 - 1
運算:1和4相與
大家注意看紅字部分,還有框出來的那一列,這一列為0,導致,最終結果,肯定是比2那一行的数字小,2這行,不就是老數組的長度嗎,那你比老數組小;你比這一行小,在新數組裡,就只能在低位了。
反之,如果節點的hashcode,這一位為1,那麼,最終結果,至少是大於等於2這一行的数字,所以,會放在高位。
參考資料
https://www.jianshu.com/p/2829fe36a8dd
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準